The previous post turned out to be rather complicated. In this one, I return to much simpler matters: 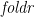 and
and 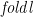 on lists, and list homomorphisms with an associative binary operator. For simplicity, I’m only going to be discussing finite lists.
on lists, and list homomorphisms with an associative binary operator. For simplicity, I’m only going to be discussing finite lists.
Fold right
Recall that is defined as follows:
![\displaystyle \begin{array}{@{}ll} \multicolumn{2}{@{}l}{\mathit{foldr} :: (\alpha \rightarrow \beta \rightarrow \beta) \rightarrow \beta \rightarrow [\alpha] \rightarrow \beta} \\ \mathit{foldr}\;(\oplus)\;e\;[\,] & = e \\ \mathit{foldr}\;(\oplus)\;e\;(a:x) & = a \oplus \mathit{foldr}\;(\oplus)\;e\;x \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7B%40%7B%7Dll%7D+%5Cmulticolumn%7B2%7D%7B%40%7B%7Dl%7D%7B%5Cmathit%7Bfoldr%7D+%3A%3A+%28%5Calpha+%5Crightarrow+%5Cbeta+%5Crightarrow+%5Cbeta%29+%5Crightarrow+%5Cbeta+%5Crightarrow+%5B%5Calpha%5D+%5Crightarrow+%5Cbeta%7D+%5C%5C+%5Cmathit%7Bfoldr%7D%5C%3B%28%5Coplus%29%5C%3Be%5C%3B%5B%5C%2C%5D+%26+%3D+e+%5C%5C+%5Cmathit%7Bfoldr%7D%5C%3B%28%5Coplus%29%5C%3Be%5C%3B%28a%3Ax%29+%26+%3D+a+%5Coplus+%5Cmathit%7Bfoldr%7D%5C%3B%28%5Coplus%29%5C%3Be%5C%3Bx+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
It satisfies the following universal property, which gives necessary and sufficient conditions for a function  to be expressible as a :
to be expressible as a :
![\displaystyle \begin{array}{@{}l} h = \mathit{foldr}\;(\oplus)\;e \quad\Longleftrightarrow\quad h\;[\,] = e \;\land\; h\;(a:x) = a \oplus (h\;x) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7B%40%7B%7Dl%7D+h+%3D+%5Cmathit%7Bfoldr%7D%5C%3B%28%5Coplus%29%5C%3Be+%5Cquad%5CLongleftrightarrow%5Cquad+h%5C%3B%5B%5C%2C%5D+%3D+e+%5C%3B%5Cland%5C%3B+h%5C%3B%28a%3Ax%29+%3D+a+%5Coplus+%28h%5C%3Bx%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
As one consequence of the universal property, we get a fusion theorem, which states sufficient conditions for fusing a following function  into a :
into a :
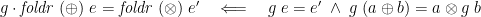
(on finite lists—infinite lists require an additional strictness condition). Fusion is an equivalence if  is surjective. If is not surjective, it’s an equivalence on the range of that fold: the left-hand side implies
is surjective. If is not surjective, it’s an equivalence on the range of that fold: the left-hand side implies
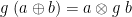
only for  of the form
of the form 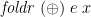 for some
for some  , not for all .
, not for all .
As a second consequence of the universal property (or alternatively, as a consequence of the free theorem of the type of ), we have map–fold fusion:
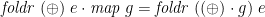
The code golf “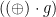 ” is a concise if opaque way of writing the binary operator pointfree:
” is a concise if opaque way of writing the binary operator pointfree: 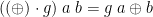 .
.
Fold left
Similarly, is defined as follows:
![\displaystyle \begin{array}{@{}ll} \multicolumn{2}{@{}l}{\mathit{foldl} :: (\beta \rightarrow \alpha \rightarrow \beta) \rightarrow \beta \rightarrow [\alpha] \rightarrow \beta} \\ \mathit{foldl}\;(\oplus)\;e\;[\,] & = e \\ \mathit{foldl}\;(\oplus)\;e\;(a:x) & = \mathit{foldl}\;(\oplus)\;(e \oplus a)\;x \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7B%40%7B%7Dll%7D+%5Cmulticolumn%7B2%7D%7B%40%7B%7Dl%7D%7B%5Cmathit%7Bfoldl%7D+%3A%3A+%28%5Cbeta+%5Crightarrow+%5Calpha+%5Crightarrow+%5Cbeta%29+%5Crightarrow+%5Cbeta+%5Crightarrow+%5B%5Calpha%5D+%5Crightarrow+%5Cbeta%7D+%5C%5C+%5Cmathit%7Bfoldl%7D%5C%3B%28%5Coplus%29%5C%3Be%5C%3B%5B%5C%2C%5D+%26+%3D+e+%5C%5C+%5Cmathit%7Bfoldl%7D%5C%3B%28%5Coplus%29%5C%3Be%5C%3B%28a%3Ax%29+%26+%3D+%5Cmathit%7Bfoldl%7D%5C%3B%28%5Coplus%29%5C%3B%28e+%5Coplus+a%29%5C%3Bx+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
( is tail recursive, so it is unproductive on an infinite list.)
also enjoys a universal property, although it’s not so well known as that for . Because of the varying accumulating parameter  , the universal property entails abstracting that argument on the left in favour of a universal quantification on the right:
, the universal property entails abstracting that argument on the left in favour of a universal quantification on the right:
![\displaystyle \begin{array}{@{}l} h = \mathit{foldl}\;(\oplus) \quad\Longleftrightarrow\quad \forall b \;.\; h\;b\;[\,] = b \;\land\; h\;b\;(a:x) = h\;(b \oplus a)\;x \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7B%40%7B%7Dl%7D+h+%3D+%5Cmathit%7Bfoldl%7D%5C%3B%28%5Coplus%29+%5Cquad%5CLongleftrightarrow%5Cquad+%5Cforall+b+%5C%3B.%5C%3B+h%5C%3Bb%5C%3B%5B%5C%2C%5D+%3D+b+%5C%3B%5Cland%5C%3B+h%5C%3Bb%5C%3B%28a%3Ax%29+%3D+h%5C%3B%28b+%5Coplus+a%29%5C%3Bx+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
(For the proof, see Exercise 16 in my paper with Richard Bird on arithmetic coding.)
From the universal property, it is straightforward to prove a map– fusion theorem:
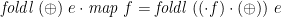
Note that 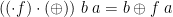 . There is also a fusion theorem:
. There is also a fusion theorem:
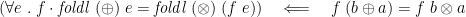
This is easy to prove by induction. (I would expect it also to be a consequence of the universal property, but I don’t see how to make that go through.)
Duality theorems
Of course, and are closely related. §3.5.1 of Bird and Wadler’s classic text presents a First Duality Theorem:
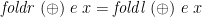
when 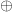 is associative with neutral element ; a more general Second Duality Theorem:
is associative with neutral element ; a more general Second Duality Theorem:
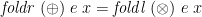
when associates with 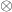 (that is,
(that is, 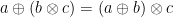 ) and
) and 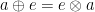 (for all
(for all 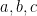 , but fixed ); and a Third Duality Theorem:
, but fixed ); and a Third Duality Theorem:
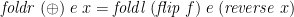
(again, all three only for finite ).
The First Duality Theorem is a specialization of the Second, when 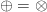 (but curiously, also a slight strengthening: apparently all we require is that
(but curiously, also a slight strengthening: apparently all we require is that 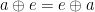 , not that both equal
, not that both equal  ; for example, we still have
; for example, we still have  , even though
, even though  is not the neutral element for
is not the neutral element for 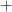 ).
).
Characterization
“When is a function a fold?” Evidently, if function on lists is injective, then it can be written as a : in that case (at least, classically speaking), has a post-inverse—a function such that 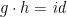 —so:
—so:
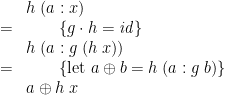
and so, letting ![{e = h\;[\,]}](https://s0.wp.com/latex.php?latex=%7Be+%3D+h%5C%3B%5B%5C%2C%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) , we have
, we have

But also evidently, injectivity is not necessary for a function to be a fold; after all, 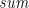 is a fold, but not the least bit injective. Is there a simple condition that is both sufficient and necessary for a function to be a fold? There is! The condition is that lists equivalent under remain equivalent when extended by an element:
is a fold, but not the least bit injective. Is there a simple condition that is both sufficient and necessary for a function to be a fold? There is! The condition is that lists equivalent under remain equivalent when extended by an element:
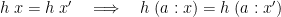
We say that is leftwards. (The kernel 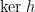 of a function is a relation on its domain, namely the set of pairs
of a function is a relation on its domain, namely the set of pairs  such that
such that 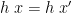 ; this condition is equivalent to
; this condition is equivalent to 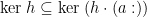 for every .) Clearly, leftwardsness is necessary: if
for every .) Clearly, leftwardsness is necessary: if 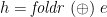 and , then
and , then
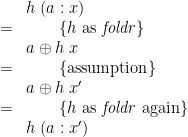
Moreover, leftwardsness is sufficient. For, suppose that is leftwards; then pick a function such that, when is in the range of , we get 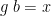 for some such that
for some such that 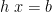 (and it doesn’t matter what value returns for outside the range of ), and then define
(and it doesn’t matter what value returns for outside the range of ), and then define
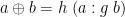
This is a proper definition of , on account of leftwardsness, in the sense that it doesn’t matter which value we pick for 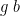 , as long as indeed : any other value
, as long as indeed : any other value  that also satisfies
that also satisfies 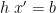 entails the same outcome
entails the same outcome 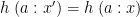 for
for 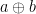 . Intuitively, it is not necessary to completely invert (as we did in the injective case), provided that preserves enough distinctions. For example, for
. Intuitively, it is not necessary to completely invert (as we did in the injective case), provided that preserves enough distinctions. For example, for 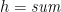 (for which indeed
(for which indeed 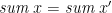 implies
implies 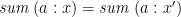 ), we could pick
), we could pick ![{g\;b = [b]}](https://s0.wp.com/latex.php?latex=%7Bg%5C%3Bb+%3D+%5Bb%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) . In particular,
. In particular, 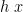 is obviously in the range of ; then
is obviously in the range of ; then 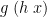 is chosen to be some such that
is chosen to be some such that 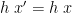 , and so by construction
, and so by construction 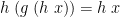 —in other words, acts as a kind of partial inverse of . So we get:
—in other words, acts as a kind of partial inverse of . So we get:
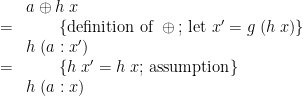
and therefore where .
Monoids and list homomorphisms
A list homomorphism is a fold after a map in a monoid. That is, define
![\displaystyle \begin{array}{@{}ll} \multicolumn{2}{@{}l}{\mathit{hom} :: (\beta\rightarrow\beta\rightarrow\beta) \rightarrow (\alpha\rightarrow\beta) \rightarrow \beta \rightarrow [\alpha] \rightarrow \beta} \\ \mathit{hom}\;(\odot)\;f\;e\;[\,] & = e \\ \mathit{hom}\;(\odot)\;f\;e\;[a] & = f\;a \\ \mathit{hom}\;(\odot)\;f\;e\;(x \mathbin{{+}\!\!\!{+}} y) & = \mathit{hom}\;(\odot)\;f\;e\;x \;\odot\; \mathit{hom}\;(\odot)\;f\;e\;y \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7B%40%7B%7Dll%7D+%5Cmulticolumn%7B2%7D%7B%40%7B%7Dl%7D%7B%5Cmathit%7Bhom%7D+%3A%3A+%28%5Cbeta%5Crightarrow%5Cbeta%5Crightarrow%5Cbeta%29+%5Crightarrow+%28%5Calpha%5Crightarrow%5Cbeta%29+%5Crightarrow+%5Cbeta+%5Crightarrow+%5B%5Calpha%5D+%5Crightarrow+%5Cbeta%7D+%5C%5C+%5Cmathit%7Bhom%7D%5C%3B%28%5Codot%29%5C%3Bf%5C%3Be%5C%3B%5B%5C%2C%5D+%26+%3D+e+%5C%5C+%5Cmathit%7Bhom%7D%5C%3B%28%5Codot%29%5C%3Bf%5C%3Be%5C%3B%5Ba%5D+%26+%3D+f%5C%3Ba+%5C%5C+%5Cmathit%7Bhom%7D%5C%3B%28%5Codot%29%5C%3Bf%5C%3Be%5C%3B%28x+%5Cmathbin%7B%7B%2B%7D%5C%21%5C%21%5C%21%7B%2B%7D%7D+y%29+%26+%3D+%5Cmathit%7Bhom%7D%5C%3B%28%5Codot%29%5C%3Bf%5C%3Be%5C%3Bx+%5C%3B%5Codot%5C%3B+%5Cmathit%7Bhom%7D%5C%3B%28%5Codot%29%5C%3Bf%5C%3Be%5C%3By+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
provided that 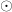 and form a monoid. (One may verify that this condition is sufficient for the equations to completely define the function; moreover, they are almost necessary— and should form a monoid on the range of
and form a monoid. (One may verify that this condition is sufficient for the equations to completely define the function; moreover, they are almost necessary— and should form a monoid on the range of 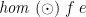 .) The Haskell library
.) The Haskell library 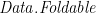 defines an analogous method, whose list instance is
defines an analogous method, whose list instance is
![\displaystyle \mathit{foldMap} :: \mathit{Monoid}\;\beta \Rightarrow (\alpha \rightarrow \beta) \rightarrow [\alpha] \rightarrow \beta](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathit%7BfoldMap%7D+%3A%3A+%5Cmathit%7BMonoid%7D%5C%3B%5Cbeta+%5CRightarrow+%28%5Calpha+%5Crightarrow+%5Cbeta%29+%5Crightarrow+%5B%5Calpha%5D+%5Crightarrow+%5Cbeta+&bg=ffffff&fg=000000&s=0&c=20201002)
—the binary operator and initial value are determined implicitly by the 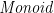 instance rather than being passed explicitly.
instance rather than being passed explicitly.
Richard Bird’s Introduction to the Theory of Lists states implicitly what might be called the First Homomorphism Theorem, that any homomorphism consists of a reduction after a map (in fact, a consequence of the free theorem of the type of 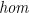 ):
):
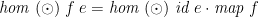
Explicitly as Lemma 4 (“Specialization”) the same paper states a Second Homomorphism Theorem, that any homomorphism can be evaluated right-to-left or left-to-right, among other orders:

I wrote up the Third Homomorphism Theorem, which is the converse of the Second Homomorphism Theorem: any function that can be written both as a and as a is a homomorphism. I learned this theorem from David Skillicorn, but it was conjectured earlier by Richard Bird and proved by Lambert Meertens during a train journey in the Netherlands—as the story goes, Lambert returned from a bathroom break with the idea for the proof. Formally, for given , if there exists 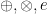 such that
such that
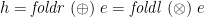
then there also exists  and associative such that
and associative such that

Recall that is “leftwards” if
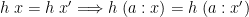
and that the leftwards functions are precisely the s. Dually, is rightwards if
![\displaystyle h\;x = h\;x' \Longrightarrow h\;(x \mathbin{{+}\!\!\!{+}} [a]) = h\;(x' \mathbin{{+}\!\!\!{+}} [a])](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++h%5C%3Bx+%3D+h%5C%3Bx%27+%5CLongrightarrow+h%5C%3B%28x+%5Cmathbin%7B%7B%2B%7D%5C%21%5C%21%5C%21%7B%2B%7D%7D+%5Ba%5D%29+%3D+h%5C%3B%28x%27+%5Cmathbin%7B%7B%2B%7D%5C%21%5C%21%5C%21%7B%2B%7D%7D+%5Ba%5D%29+&bg=ffffff&fg=000000&s=0&c=20201002)
and (as one can show) the rightwards functions are precisely the s. So the Specialization Theorem states that every homomorphism is both leftwards and rightwards, and the Third Homomorphism Theorem states that every function that is both leftwards and rightwards is necessarily a homomorphism. To prove the latter, suppose that is both leftwards and rightwards; then pick a function such that, for in the range of , we get for some such that , and then define
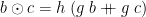
As before, this is a proper definition of : assuming leftwardsness and rightwardsness, the result does not depend on the representatives chosen for . By construction, again satisfies for any , and so we have:

Moreover, one can show that is associative, and its neutral element (at least on the range of ).
For example, sorting a list can obviously be done as a , using insertion sort; by the Third Duality Theorem, it can therefore also be done as a on the reverse of the list; and because the order of the input is irrelevant, the reverse can be omitted. The Third Homomorphism Theorem then implies that there exists an associative binary operator such that 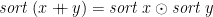 . It also gives a specification of , given a suitable partial inverse of
. It also gives a specification of , given a suitable partial inverse of 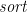 —in this case,
—in this case, 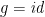 suffices, because is idempotent. The only characterization of arising directly from the proof involves repeatedly inserting the elements of one argument into the other, which does not exploit sortedness of the first argument. But from this inefficient characterization, one may derive the more efficient implementation that merges two sorted sequences, and hence obtain merge sort overall.
suffices, because is idempotent. The only characterization of arising directly from the proof involves repeatedly inserting the elements of one argument into the other, which does not exploit sortedness of the first argument. But from this inefficient characterization, one may derive the more efficient implementation that merges two sorted sequences, and hence obtain merge sort overall.
The Trick
Here is another relationship between the directed folds ( and ) and list homomorphisms—any directed fold can be implemented as a homomorphism, followed by a final function application to a starting value:
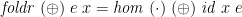
Roughly speaking, this is because application and composition are related:
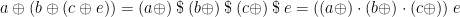
(here, 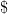 is right-associating, loose-binding function application). To be more precise:
is right-associating, loose-binding function application). To be more precise:

This result has many applications. For example, it’s the essence of parallel recognizers for regular languages. Language recognition looks at first like an inherently sequential process; a recognizer over an alphabet  can be represented as a finite state machine over states
can be represented as a finite state machine over states  , with a state transition function of type
, with a state transition function of type 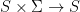 , and such a function is clearly not associative. But by mapping this function over the sequence of symbols, we get a sequence of
, and such a function is clearly not associative. But by mapping this function over the sequence of symbols, we get a sequence of 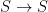 functions, which should be subject to composition. Composition is of course associative, so can be computed in parallel, in
functions, which should be subject to composition. Composition is of course associative, so can be computed in parallel, in 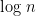 steps on
steps on  processors. Better yet, each such function can be represented as an array (since is finite), and the composition of any number of such functions takes a fixed amount of space to represent, and a fixed amount of time to apply, so the steps take time.
processors. Better yet, each such function can be represented as an array (since is finite), and the composition of any number of such functions takes a fixed amount of space to represent, and a fixed amount of time to apply, so the steps take time.
Similarly for carry-lookahead addition circuits. Binary addition of two -bit numbers with an initial carry-in proceeds from right to left, adding bit by bit and taking care of carries, producing an -bit result and a carry-out; this too appears inherently sequential. But there aren’t many options for the pair of input bits at a particular position: two s will always generate an outgoing carry, two  s will always kill an incoming carry, and a and in either order will propagate an incoming carry to an outgoing one. Whether there is a carry-in at a particular bit position is computed by a of the bits to the right of that position, zipped together, starting from the initial carry-in, using the binary operator defined by
s will always kill an incoming carry, and a and in either order will propagate an incoming carry to an outgoing one. Whether there is a carry-in at a particular bit position is computed by a of the bits to the right of that position, zipped together, starting from the initial carry-in, using the binary operator defined by
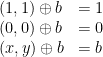
Again, applying to a bit-pair makes a bit-to-bit function; these functions are to be composed, and function composition is associative. Better, such functions have small finite representations as arrays (indeed, we need a domain of only three elements, 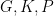 ;
;  and
and  are both left zeroes of composition, and
are both left zeroes of composition, and  is neutral). Better still, we can compute the carry-in at all positions using a
is neutral). Better still, we can compute the carry-in at all positions using a 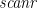 , which for an associative binary operator can also be performed in parallel in steps on processors.
, which for an associative binary operator can also be performed in parallel in steps on processors.
The Trick seems to be related to Cayley’s Theorem, on monoids rather than groups: any monoid is equivalent to a monoid of endomorphisms. That is, corresponding to every monoid 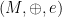 , with
, with  a set, and
a set, and  an associative binary operator with neutral element
an associative binary operator with neutral element 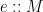 , there is another monoid
, there is another monoid 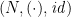 on the carrier
on the carrier 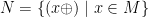 of endomorphisms of the form
of endomorphisms of the form 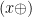 ; the mappings
; the mappings 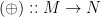 and
and 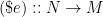 are both monoid homomorphisms, and are each other’s inverse. (Cayley’s Theorem is what happens to the Yoneda Embedding when specialized to the one-object category representing a monoid.) So any list homomorphism corresponds to a list homomorphism with endomorphisms as the carrier, followed by a single final function application:
are both monoid homomorphisms, and are each other’s inverse. (Cayley’s Theorem is what happens to the Yoneda Embedding when specialized to the one-object category representing a monoid.) So any list homomorphism corresponds to a list homomorphism with endomorphisms as the carrier, followed by a single final function application:

Note that 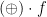 takes a list element the endomorphism
takes a list element the endomorphism 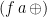 . The change of representation from to
. The change of representation from to  is the same as in The Trick, and is also what underlies Hughes’s novel representation of lists; but I can’t quite put my finger on what these both have to do with Cayley and Yoneda.
is the same as in The Trick, and is also what underlies Hughes’s novel representation of lists; but I can’t quite put my finger on what these both have to do with Cayley and Yoneda.


Hi Jeremy,
The last equivalence, hom (+) f e = ($ e) . hom (.) ((+) . f) id, can be explained by naturality in the monoid parameter. It’s more obvious if you write it as:
hom :: Monoid m => (a -> m) -> ([a] -> m)
Because the monoid parameter occurs both co- and contra-variantly, you need a monoid isomorphism, which you have between M and N.
Cheers,
Tom
Only the first half of the above explanation is right. Let me explain it properly in more detail.
As you have already observed, your hom is equivalent to
foldMap :: Monoid m => (a -> m) -> ([a] -> m).
Let’s specialize this for a given element type A and call it fM.
We can then see this as a natural transformation fM : F -> G
where F and G are functors from the category Mon to the category Set.
F : Mon -> Set
F(M,(+),e) = A -> M
F(f) = \g -> f . g
G : Mon -> Set
G(M,(+),e) = [A] -> M
G(f) = \g -> f . g
As you have already pointed out, for any given monoid (M,(+),e) the Yoneda embedding yields a monoid (N,(.),id). The functions ($e) :: N -> M and (+) :: M -> N are monoid homomorphisms between these two monoids such that ($e) . (+) = id_M (*).
Then we can calculate:
fm_M
= (category)
id_GM . fm_M
= (functor)
G(id_M) . fm_M
= (*)
G(($e) . (+)) . fm_M
= (functor)
G(($e)) . G((+)) . fm_M
= (naturality)
G(($e)) . fm_N . F((+))
If we expand the above we get the equation
foldMap f = ($e) . foldMap ((+) . f)
or even more explicitly
hom (+) f e = ($ e) . hom (.) ((+) . f) id
Key here was the appeal to naturality. I believe that the Trick can be proven also by two appeals to naturality, one for each type parameter of foldr, one of which is the element type and the other the algebra.
Cheers,
Tom
Hi Jeremy,
Following our personal conversation, here is another note about your interesting post.
I believe that your universal property of left folds is not as universal as it could be. For one, as you point out, it does not allow you to show the fusion property.
You have pointed out to me that there is a non-standard definition of foldl by Richard Bird that is dual to the standard foldr definition:
foldl (+) e [] = e
foldl (+) e (xs ++ [x]) = foldl (+) e xs + x
This suggests directly a universal property formulation that is dual to that of foldr:
h = foldl (+) e h [] = e /\ (forall x xs. h (xs ++ [x]) = h xs + x)
This formulation does enable the fusion property:
f . foldl (+) e = foldl (*) (f e) <= forall a b. f (a + b) = f a * b
Indeed, we can show that the two conditions of the universal property are met:
f (foldl (+) e [])
= def foldl
f e
f (foldl (+) e (xs ++ [x])
= def foldl
f (foldl (+) e xs + x)
= precondition of fusion
f (foldl (+) e xs) * x
Moreover, I believe that my formulation is more general than yours because it does not require the function h to be written in a form that is parametric in an accumulator value. If the function is already written in that style, then I believe that the two properties are equivalent. Yet, for instance, for the fusion property we do not have a formulation in that style, which is why your formulation does not fit.
Also, I believe that neither universal property covers infinite lists — foldl seems to make sense only for finite lists.
Cheers,
Tom
Thanks, Tom!
Pingback: Resumen de lecturas compartidas durante agosto de 2018 | Vestigium