
Continuing my work in regress, this post revisits—with the benefit of much hindsight—what I was working on for my DPhil thesis (which was summarized in a paper at MPC 1992) and in subsequent papers at MPC 1998 and in SCP in 2000. This is the topic of accumulations on data structures, which distribute information across the data structure. List instances are familiar from the Haskell standard libraries (and, to those with a long memory, from APL); my thesis presented instances for a variety of tree datatypes; and the later work was about making it datatype-generic. I now have a much better way of doing it, using Conor McBride’s derivatives.
Accumulations
Accumulations or scans distribute information contained in a data structure across that data structure in a given direction. The paradigmatic example is computing the running totals of a list of numbers, which can be thought of as distributing the numbers rightwards across the list, summing them as you go. In Haskell, this is an instance of the 
![\displaystyle \begin{array}{lcl} \mathit{scanl} &::& (\beta \rightarrow \alpha \rightarrow \beta) \rightarrow \beta \rightarrow [\alpha] \rightarrow [\beta] \\ \mathit{scanl}\,f\,e\,[\,] &=& [e] \\ \mathit{scanl}\,f\,e\,(a:x) &=& e : \mathit{scanl}\,f\,(f\,e\,a)\,x \medskip \\ \mathit{totals} &::& [{\mathbb Z}] \rightarrow [{\mathbb Z}] \\ \mathit{totals} &=& \mathit{scanl}\,(+)\,0 \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Blcl%7D+%5Cmathit%7Bscanl%7D+%26%3A%3A%26+%28%5Cbeta+%5Crightarrow+%5Calpha+%5Crightarrow+%5Cbeta%29+%5Crightarrow+%5Cbeta+%5Crightarrow+%5B%5Calpha%5D+%5Crightarrow+%5B%5Cbeta%5D+%5C%5C+%5Cmathit%7Bscanl%7D%5C%2Cf%5C%2Ce%5C%2C%5B%5C%2C%5D+%26%3D%26+%5Be%5D+%5C%5C+%5Cmathit%7Bscanl%7D%5C%2Cf%5C%2Ce%5C%2C%28a%3Ax%29+%26%3D%26+e+%3A+%5Cmathit%7Bscanl%7D%5C%2Cf%5C%2C%28f%5C%2Ce%5C%2Ca%29%5C%2Cx+%5Cmedskip+%5C%5C+%5Cmathit%7Btotals%7D+%26%3A%3A%26+%5B%7B%5Cmathbb+Z%7D%5D+%5Crightarrow+%5B%7B%5Cmathbb+Z%7D%5D+%5C%5C+%5Cmathit%7Btotals%7D+%26%3D%26+%5Cmathit%7Bscanl%7D%5C%2C%28%2B%29%5C%2C0+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
A special case of this pattern is to distribute the elements of a list rightwards across the list, simply collecting them as you go, rather than summing them. That’s the 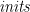
![\displaystyle \mathit{inits} = \mathit{scanl}\,\mathit{snoc}\,[\,] \quad\mathbf{where}\; \mathit{snoc}\,x\,a = x \mathbin{{+}\!\!\!{+}} [a]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathit%7Binits%7D+%3D+%5Cmathit%7Bscanl%7D%5C%2C%5Cmathit%7Bsnoc%7D%5C%2C%5B%5C%2C%5D+%5Cquad%5Cmathbf%7Bwhere%7D%5C%3B+%5Cmathit%7Bsnoc%7D%5C%2Cx%5C%2Ca+%3D+x+%5Cmathbin%7B%7B%2B%7D%5C%21%5C%21%5C%21%7B%2B%7D%7D+%5Ba%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
It’s particularly special, in the sense that it is the most basic
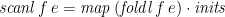
This is called the Scan Lemma for 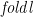


However, the left-to-right operators 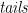
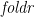
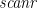
Upwards and downwards accumulations on binary trees
What would

for which the obvious fold operator is

I’m taking the view that the appropriate generalization is to distribute data “upwards” and “downwards” through such a tree—from the leaves towards the root, and vice versa. This does indeed specialize to the definitions we had on lists when you view them vertically in terms of their “cons” structure: they’re long thin trees, in which every parent has exactly one child. (An alternative view would be to look at distributing data horizontally through a tree, from left to right and vice versa. Perhaps I’ll come back to that another time.)
The upwards direction is the easier one to deal with. An upwards accumulation labels every node of the tree with some function of its descendants; moreover, the descendants of a node themselves form a tree, so can be easily represented, and folded. So we can quite straightforwardly define:

where 
As with lists, the most basic upwards scan uses the constructors themselves as arguments:

and any other scan can be expressed, albeit less efficiently, in terms of this:

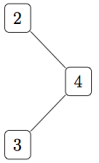
The downwards direction is more difficult, though. A downwards accumulation should label every node with some function of its ancestors; but these do not form another tree. For example, in the homogeneous binary tree

the ancestors of the node labelled 

![{[2,4,3]}](https://s0.wp.com/latex.php?latex=%7B%5B2%2C4%2C3%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

(I called them “threads” in my thesis.) Then we can capture the data structure representing the ancestors of the node labelled
by the expression 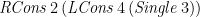

to compute the tree giving the ancestors of every node, and for a corresponding 
Generic upwards accumulations
Having seen ad-hoc constructions for a particular kind of binary tree, we should consider what the datatype-generic construction looks like. I discussed datatype-generic upwards accumulations already, in the post on Horner’s Rule; the construction was given in the paper Generic functional programming with types and relations by Richard Bird, Oege de Moor and Paul Hoogendijk. As with homogeneous binary trees, it’s still the case that the generic version of 


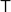
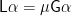

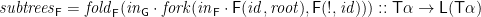
where 
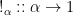

Generic downwards accumulations, via linearization
The best part of a decade after my thesis work, inspired by the paper by Richard Bird & co, I set out to try to define datatype-generic versions of downward accumulations too. I wrote a paper about it for MPC 1998, and then came up with a new construction for the journal version of that paper in SCP in 2000. I now think these constructions are rather clunky, and I have a better one; if you don’t care to explore the culs-de-sac, skip this section and the next and go straight to the section on derivatives.
The MPC construction was based around a datatype-generic version of the 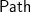

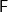
The construction in the paper assumed that

where each 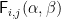


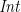


the shape functor is 

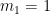
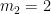
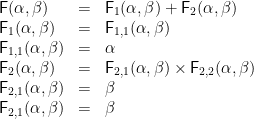
Then for each 

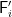
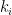



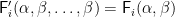
and
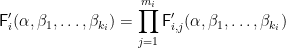
where 


Having defined the linear variant 

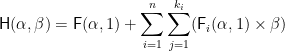
That is, paths are a kind of non-empty cons list. The path ends at some node of the original data structure; so the last element of the path is of type 



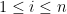

For example, for leaf-labelled binary trees, the “local content” for the last element of the path is either a single label (for tips) or void (for bins), and for the other path elements, there are zero copies of the local content for a tip (because a tip has zero children), and two copies of the void local information for bins (because a bin has two children). Therefore, the path datatype for such trees is

which is isomorphic to the definition that you might have written yourself:
For homogeneous binary trees, the construction gives
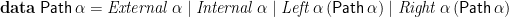
which is almost the ad-hoc definition we had two sections ago, except that it distinguishes singleton paths that terminate at an external node from those that terminate at an internal one.
Now, analogous to the function 
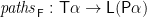
![\displaystyle \begin{array}{lcl} \mathit{inits}\,[\,] &=& [[\,]] \\ \mathit{inits}\,(a:x) &=& [\,] : \mathit{map}\,(a:)\,(\mathit{inits}\,x) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Blcl%7D+%5Cmathit%7Binits%7D%5C%2C%5B%5C%2C%5D+%26%3D%26+%5B%5B%5C%2C%5D%5D+%5C%5C+%5Cmathit%7Binits%7D%5C%2C%28a%3Ax%29+%26%3D%26+%5B%5C%2C%5D+%3A+%5Cmathit%7Bmap%7D%5C%2C%28a%3A%29%5C%2C%28%5Cmathit%7Binits%7D%5C%2Cx%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
A second definition is as an unfold, maintaining as an accumulating parameter of type 
![\displaystyle \begin{array}{lcl} \mathit{inits} &=& \mathit{inits}'\,\mathit{id} \medskip \\ \mathit{inits}'\,f\,[\,] &=& f\,[\,] \\ \mathit{inits}'\,f\,(a:x) &=& f\,[\,] : \mathit{inits}'\,(f \cdot (a:))\,x \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Blcl%7D+%5Cmathit%7Binits%7D+%26%3D%26+%5Cmathit%7Binits%7D%27%5C%2C%5Cmathit%7Bid%7D+%5Cmedskip+%5C%5C+%5Cmathit%7Binits%7D%27%5C%2Cf%5C%2C%5B%5C%2C%5D+%26%3D%26+f%5C%2C%5B%5C%2C%5D+%5C%5C+%5Cmathit%7Binits%7D%27%5C%2Cf%5C%2C%28a%3Ax%29+%26%3D%26+f%5C%2C%5B%5C%2C%5D+%3A+%5Cmathit%7Binits%7D%27%5C%2C%28f+%5Ccdot+%28a%3A%29%29%5C%2Cx+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Even with an accumulating “Hughes list” parameter, it still takes quadratic time.)
The downwards accumulation itself is defined as a path fold mapped over the paths, giving a Scan Lemma for downwards accumulations. With either the fold or the unfold definition of paths, this is still quadratic, again because of the lack of common subexpressions in a result of quadratic size. However, in some circumstances the path fold can be reassociated (analogous to turning a
Generic downwards accumulations, via zip
I was dissatisfied with the “…”s in the MPC construction of datatype-generic paths, but couldn’t see a good way of avoiding them. So in the subsequent SCP version of the paper, I presented an alternative construction of downwards accumulations, which does not go via a definition of paths; instead, it goes directly to the accumulation itself.
As with the efficient version of the MPC construction, it is coinductive, and uses an accumulating parameter to carry in to each node the seed from higher up in the tree; so the downwards accumulation is of type 


The result 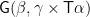
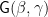

These two components get combined to make the whole result via a function

This will be partial in general, defined only for pairs of 
The second component of 
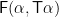

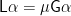
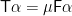
For the first component, we enforce the constraint that all output labels are dependent only on their ancestors by unpacking the 

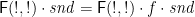
where 

The SCP construction gets rid of the “…”s in the MPC construction. It is also inherently efficient, in the sense that if the core operation
Generic downwards accumulations, via derivatives
After another interlude of about a decade, and with the benefit of new results to exploit, I had a “eureka” moment: the linearization of a shape functor is closely related to the beautiful notion of the derivative of a datatype, as promoted by Conor McBride. The crucial observation Conor made is that the “one-hole contexts” of a datatype—that is, for a container datatype, the datatype of data structures with precisely one element missing—can be neatly formalized using an analogue of the rules of differential calculus. The one-hole contexts are precisely what you need to identify which particular child you’re talking about out of a collection of children. (If you’re going to follow along with some coding, I recommend that you also read Conor’s paper Clowns to the left of me, jokers to the right. This gives the more general construction of dissecting a datatype, identifying a unique hole, but also allowing the “clowns” to the left of the hole to have a different type from the “jokers” to the right. I think the explanation of the relationship with the differential calculus is much better explained here; the original notion of derivative can be retrieved by specializing the clowns and jokers to the same type.)
The essence of the construction is the notion of a derivative 

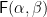

That’s how to consume one-hole contexts; how can we produce them? We could envisage some kind of inverse 

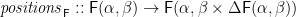
One property of 
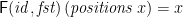
A second property relates it to

(I believe that those two properties completely determine
Incidentally, the derivative 
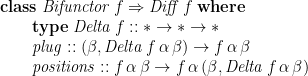
Conor’s papers show how to define instances of
The path to a node in a data structure is simply a list of one-hole contexts—let’s say, innermost context first, although it doesn’t make much difference—but with all the data off the path (that is, the other children) stripped away:
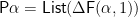
This is a projection of Huet’s zipper, which preserves the off-path children, and records also the subtree in focus at the end of the path:

Since the contexts are listed innermost-first in the path, closing up a zipper to reconstruct a tree is a

Now, let’s develop the function 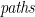
![\displaystyle \begin{array}{lcl} \mathit{paths}_\mathsf{F} &::& \mathsf{T}\alpha \rightarrow \mathsf{L}(\mathsf{P}\alpha) \\ \mathit{paths}_\mathsf{F}\,t &=& \mathit{paths}'_\mathsf{F}\,(t,[\,]) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Blcl%7D+%5Cmathit%7Bpaths%7D_%5Cmathsf%7BF%7D+%26%3A%3A%26+%5Cmathsf%7BT%7D%5Calpha+%5Crightarrow+%5Cmathsf%7BL%7D%28%5Cmathsf%7BP%7D%5Calpha%29+%5C%5C+%5Cmathit%7Bpaths%7D_%5Cmathsf%7BF%7D%5C%2Ct+%26%3D%26+%5Cmathit%7Bpaths%7D%27_%5Cmathsf%7BF%7D%5C%2C%28t%2C%5B%5C%2C%5D%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Given the components 

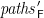





That is,

Downwards accumulations are then path functions mapped over the result of

Moreover, it is straightforward to fuse the 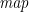
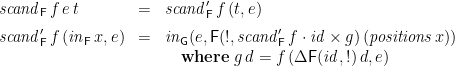
which takes time linear in the size of the tree, assuming that 
Finally, in the case that the function being mapped over the paths is a

Isn’t the type of scanl in the first paragraph of code incorrect? That is, the last type should be [alpha] rather than just alpha.
Oops. Fixed, thanks. (And I’ve swapped the alpha and betas for consistency with what follows.)