Inspired by Bob Harper’s recent postings, I too have a confession to make. I know what is morally right; but sometimes the temptation is too great, and my resolve is weak, and I lapse. Fast and loose reasoning may excuse me, but my conscience would be clearer if I could remain pure in the first place.
Initial algebras, final coalgebras
We know and love initial algebras, because of the ease of reasoning with their universal properties. We can tell a simple story about recursive programs, solely in terms of sets and total functions. As we discussed in the previous post, given a functor  , an
, an 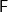 -algebra is a pair
-algebra is a pair 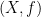 consisting of an object
consisting of an object  and an arrow
and an arrow 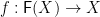 . A homomorphism between -algebras and
. A homomorphism between -algebras and  is an arrow
is an arrow 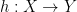 such that
such that 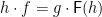 :
:

The -algebra is initial iff there is a unique such  for each ; for well-behaved functors , such as the polynomial functors on
for each ; for well-behaved functors , such as the polynomial functors on 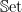 , an initial algebra always exists. We conventionally write “
, an initial algebra always exists. We conventionally write “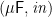 ” for the initial algebra, and “
” for the initial algebra, and “ ” for the unique homomorphism to another -algebra . (In , initial algebras correspond to datatypes of finite recursive data structures.)
” for the unique homomorphism to another -algebra . (In , initial algebras correspond to datatypes of finite recursive data structures.)

The uniqueness of the solution is captured in the universal property:

In words, is this fold iff satisfies the defining equation for the fold.
The universal property is crucial. For one thing, the homomorphism equation is a very convenient style in which to define a function; it’s the datatype-generic abstraction of the familiar pattern for defining functions on lists:
![\displaystyle \begin{array}{lcl} h\,[] &=& e \\ h\,(x:\mathit{xs}) &=& f\,x\,(h\,\mathit{xs}) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Blcl%7D+h%5C%2C%5B%5D+%26%3D%26+e+%5C%5C+h%5C%2C%28x%3A%5Cmathit%7Bxs%7D%29+%26%3D%26+f%5C%2Cx%5C%2C%28h%5C%2C%5Cmathit%7Bxs%7D%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
These two equations implicitly characterizing are much more comprehensible and manipulable than a single equation

explicitly giving a value for . But how do we know that this assortment of two facts about is enough to form a definition? Of course! A system of equations in this form has a unique solution.
Moreover, the very expression of the uniqueness of the solution as an equivalence  provides many footholds for reasoning:
provides many footholds for reasoning:
- Read as an implication from left to right, instantiating to
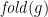 to make the left-hand side trivially true, we get an evaluation rule for folds:
to make the left-hand side trivially true, we get an evaluation rule for folds:

- Read as an implication from right to left, we get a proof rule for demonstrating that some complicated expression is a fold:

- In particular, we can quickly see that the identity function is a fold:

so  . (In fact, this one’s an equivalence.)
. (In fact, this one’s an equivalence.)
- We get a very simple proof of a fusion rule, for combining a following function with a fold to make another fold:
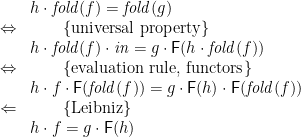
- Using this, we can deduce Lambek’s Lemma, that the constructors
 form an isomorphism. Supposing that there is a right inverse, and it is a fold, what must it look like?
form an isomorphism. Supposing that there is a right inverse, and it is a fold, what must it look like?

So if we define  , we get
, we get  . We should also check the left inverse property:
. We should also check the left inverse property:

And so on, and so on. Many useful functions can be written as instances of 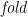 , and the universal property gives us a very powerful reasoning tool—the universal property of is a marvel to behold.
, and the universal property gives us a very powerful reasoning tool—the universal property of is a marvel to behold.
And of course, it all dualizes beautifully. An -coalgebra is a pair with  . A homomorphism between -coalgebras and is a function such that
. A homomorphism between -coalgebras and is a function such that  :
:

The -coalgebra is final iff there is a unique homomorphism to it from each ; again, for well-behaved , final coalgebras always exist. We write “ ” for the final coalgebra, and
” for the final coalgebra, and  for the unique homomorphism to it. (In , final coalgebras correspond to datatypes of finite-or-infinite recursive data structures.)
for the unique homomorphism to it. (In , final coalgebras correspond to datatypes of finite-or-infinite recursive data structures.)

Uniqueness is captured by the universal property

which has just as many marvellous consequences. Many other useful functions are definable as instances of 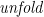 , and again the universal property gives a very powerful tool for reasoning with them.
, and again the universal property gives a very powerful tool for reasoning with them.
Hylomorphisms
There are also many interesting functions that are best described as a combination of a fold and an unfold. The hylomorphism pattern, with an unfold followed by a fold, is the best known: the unfold produces a recursive structure, which the fold consumes.
The factorial function is a simple example. The datatype of lists of natural numbers is determined by the shape functor
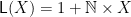
Then we might hope to write

where 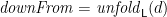 and
and  with
with

More elaborately, we might hope to write 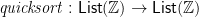 as the composition of
as the composition of  (to generate a binary search tree) and
(to generate a binary search tree) and 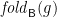 (to flatten that tree to a list), where
(to flatten that tree to a list), where 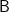 is the shape functor for internally-labelled binary trees,
is the shape functor for internally-labelled binary trees,
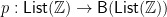
partitions a list of integers into the unit or a pivot and two sublists, and

glues together the unit or a pivot and two sorted lists into one list. In fact, any divide-and-conquer algorithm can be expressed in terms of an unfold computing a tree of subproblems top-down, followed by a fold that solves the subproblems bottom-up.
But sadly, this doesn’t work in , because the types don’t meet in the middle. The source type of the fold is (the carrier of) an initial algebra, but the target type of the unfold is a final coalgebra, and these are different constructions.
This is entirely reasonable, when you think about it. Our definitions in —the category of sets and total functions—necessarily gave us folds and unfolds as total functions; the composition of two total functions is a total function, and so a fold after an unfold ought to be a total function too. But it is easy to define total instances of that generate infinite data structures (such as a function  , which generates an infinite ascending list of naturals), on which a following fold is undefined (such as “the product” of an infinite ascending list of naturals). The composition then should not be a total function.
, which generates an infinite ascending list of naturals), on which a following fold is undefined (such as “the product” of an infinite ascending list of naturals). The composition then should not be a total function.
One might try interposing a conversion function of type 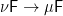 , coercing the final data structure produced by the unfold into an initial data structure for consumption by the fold. But there is no canonical way of doing this, because final data structures may be “bigger” (perhaps infinitely so) than initial ones. (In contrast, there is a canonical function of type
, coercing the final data structure produced by the unfold into an initial data structure for consumption by the fold. But there is no canonical way of doing this, because final data structures may be “bigger” (perhaps infinitely so) than initial ones. (In contrast, there is a canonical function of type 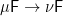 . In fact, there are two obvious definitions of it, and they agree—a nice exercise!)
. In fact, there are two obvious definitions of it, and they agree—a nice exercise!)
One might try parametrizing that conversion function with a natural number, bounding the depth to which the final data structure is traversed. Then the coercion is nicely structural (in fact, it’s a fold over the depth), and everything works out type-wise. But having to thread such “resource bounds” through the code does terrible violence to the elegant structure; it’s not very satisfactory.
Continuous algebras
The usual solution to this conundrum is to give up on , and to admit that richer domain structures than sets and total functions are required. Specifically, in order to support recursive definitions in general, and the hylomorphism in particular, one should move to the category  of continuous functions between complete partial orders (CPOs). Now is not the place to give all the definitions; see any textbook on denotational semantics. The bottom line, so to speak, is that one has to accept a definedness ordering
of continuous functions between complete partial orders (CPOs). Now is not the place to give all the definitions; see any textbook on denotational semantics. The bottom line, so to speak, is that one has to accept a definedness ordering  on values—both on “data” and on functions—and allow some values to be less than fully defined.
on values—both on “data” and on functions—and allow some values to be less than fully defined.
Actually, in order to give meaning to all recursive definitions, one has to further restrict the setting to pointed CPOs—in which there is a least-defined “bottom” element  for each type , which can be given as the “meaning” (solution) of the degenerate recursive definition
for each type , which can be given as the “meaning” (solution) of the degenerate recursive definition  at type . Then there is no “empty” CPO; the smallest CPO
at type . Then there is no “empty” CPO; the smallest CPO  has just a single element, namely
has just a single element, namely 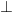 . As with colimits in general, this smallest object is used as the start of a chain of approximations to a limiting solution. But in order for really to be an initial object, one also has to constrain the arrows to be strict, that is, to preserve ; only then is there a unique arrow
. As with colimits in general, this smallest object is used as the start of a chain of approximations to a limiting solution. But in order for really to be an initial object, one also has to constrain the arrows to be strict, that is, to preserve ; only then is there a unique arrow  for each
for each  . The category of strict continuous functions between pointed CPOs is called
. The category of strict continuous functions between pointed CPOs is called 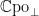 .
.
It so happens that in , initial algebras and final coalgebras coincide: the objects (pointed CPOs)  and
and  are identical. This is very convenient, because it means that the hylomorphism pattern works fine: the structure generated by the unfold is exactly what is expected by the fold.
are identical. This is very convenient, because it means that the hylomorphism pattern works fine: the structure generated by the unfold is exactly what is expected by the fold.

Of course, it still happen that the composition yields a “partial” (less than fully defined) function; but at least it now type-checks. Categories with this initial algebra/final coalgebra coincidence are called algebraically compact; they were studied by Freyd, but there’s a very good survey by Adámek, Milius and Moss.
However, the story gets murkier than that. For one thing, does not have proper products. (Indeed, an algebraically compact category with products collapses.) But beyond that, —with its restriction to strict arrows—is not a good model of lazy functional programming; , with non-strict arrows too, is better. So one needs a careful balance of the two categories. The consequences for initial algebras and final coalgebras are spelled out in one of my favourite papers, Program Calculation Properties of Continuous Algebras by Fokkinga and Meijer. In a nutshell, one can only say that the defining equation 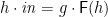 for folds has a unique strict solution in ; without the strictness side-condition,
for folds has a unique strict solution in ; without the strictness side-condition,  is unconstrained (because
is unconstrained (because 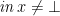 for any
for any  ). But the situation for coalgebras remains unchanged—the defining equation
). But the situation for coalgebras remains unchanged—the defining equation 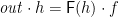 for unfolds has a unique solution (and moreover, it is strict when
for unfolds has a unique solution (and moreover, it is strict when  is strict).
is strict).
This works, but it means various strictness side-conditions have to be borne in mind when reasoning about folds. Done rigorously, it’s rather painful.
Recursive coalgebras
So, back to my confession. I want to write divide-and-conquer programs, which produce intermediate data structures and then consume them. Folds and unfolds in do not satisfy me; I want more—hylos. Morally, I realise that I should pay careful attention to those strictness side-conditions. But they’re so fiddly and boring, and my resolve is weak, so I usually just brush them aside. Is there away that I can satisfy my appetite for divide-and-conquer programs while still remaining in the pure world?
Tarmo Uustalu and colleagues have a suggestion. Final coalgebras and algebraic compactness are sufficient but not necessary for the hylo diagram above to have a unique solution; they propose to focus on recursive coalgebras instead. The -coalgebra is “recursive” iff, for each 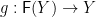 , there is a unique such that
, there is a unique such that  :
:

This is a generalization of initial algebras: if has an initial algebra , then by Lambek’s Lemma has an inverse  , and
, and 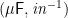 is a recursive coalgebra. And it is a strict generalization: it also covers patterns such as paramorphisms (primitive recursion)—since
is a recursive coalgebra. And it is a strict generalization: it also covers patterns such as paramorphisms (primitive recursion)—since  is a recursive
is a recursive  -coalgebra where is the functor taking to
-coalgebra where is the functor taking to 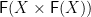 —and the “back one or two steps” pattern used in the Fibonacci function.
—and the “back one or two steps” pattern used in the Fibonacci function.
Crucially for us, almost by definition it covers all of the “reasonable” hylomorphisms too. For example,  is a recursive
is a recursive  -coalgebra, where is the shape functor for lists of naturals and
-coalgebra, where is the shape functor for lists of naturals and  the -coalgebra introduced above that analyzes a natural into nothing (for zero) or itself and its predecessor (for non-zero inputs). Which is to say, for each
the -coalgebra introduced above that analyzes a natural into nothing (for zero) or itself and its predecessor (for non-zero inputs). Which is to say, for each 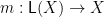 , there is a unique such that
, there is a unique such that  ; in particular, for the
; in particular, for the  given above that returns 1 or multiplies, the unique is the factorial function. (In fact, this example is also an instance of a paramorphism.) And
given above that returns 1 or multiplies, the unique is the factorial function. (In fact, this example is also an instance of a paramorphism.) And 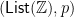 is a recursive -coalgebra, where
is a recursive -coalgebra, where  is the partition function of quicksort—for any -algebra , there is a unique such that
is the partition function of quicksort—for any -algebra , there is a unique such that  , and in particular when
, and in particular when  is the glue function for quicksort, that unique solution is quicksort itself.
is the glue function for quicksort, that unique solution is quicksort itself.
This works perfectly nicely in ; there is no need to move to more complicated settings such as or , or to consider partiality, or strictness, or definedness orderings. The only snag is the need to prove that a particular coalgebra of interest is indeed recursive. Capretta et al. study a handful of “basic” recursive coalgebras and of constructions on coalgebras that preserve recursivity.
More conveniently, Taylor and Adámek et al. relate recursivity of coalgebras to the more familiar notion of variant function, ie well-founded ordering on arguments of recursive calls. They restrict attention to finitary shape functors; technically, preserving directed colimits, but informally, I think that’s equivalent to requiring that each element of  has a finite number of elements—so polynomial functors are ok, as is the finite powerset functor, but not powerset in general. If I understand those sources right, for a finitary functor and an -coalgebra , the following conditions are equivalent: (i) is corecursive; (ii) is well-founded, in the sense that there is a well-founded ordering
has a finite number of elements—so polynomial functors are ok, as is the finite powerset functor, but not powerset in general. If I understand those sources right, for a finitary functor and an -coalgebra , the following conditions are equivalent: (i) is corecursive; (ii) is well-founded, in the sense that there is a well-founded ordering 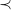 such that
such that  for each “element”
for each “element”  of
of  ; (iii) every element of
; (iii) every element of 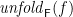 has finite depth; and (iv) there is a coalgebra homomorphism from to .
has finite depth; and (iv) there is a coalgebra homomorphism from to .
This means that I can resort to simple and familiar arguments in terms of variant functions to justify hylo-style programs. The factorial function is fine, because ( is a finitary functor, being polynomial, and) the chain of recursive calls to which leads is well-founded; quicksort is fine, because the partitioning step is well-founded; and so on. Which takes a great weight of guilt off my shoulders: I can give in to the temptation to write interesting programs, and still remain morally as pure as the driven snow.


Interesting post! I’ve written about the canonical arrow of type $μF → νF$ on my blog: http://zenzike.com/posts/2011-04-18-do-the-hokey-cokey.html
I’ve just started reading your blog. It is very interesting, but do you think you could enable full views in your RSS feed? I use Google Reader to keep track of the many blogs I read and it is quite disruptive to have to open a new tab to read the article.
Intriguing article! It makes me wonder, would the category Rel serve as a good basis for a (general-purpose) programming language?
There’s an interesting connection, isn’t there? With relational unfolds as the converses of folds (as in Bird and de Moor’s “Algebra of Programming” book), you are constrained to recursive coalgebras – at least, non-terminating unfoldings lead to simple partiality rather than bottoms. Oege de Moor and I made some steps towards relational programming in this paper: http://www.cs.ox.ac.uk/publications/publication2356-abstract.html (and of course there have been many other approaches too).
Fixed a WordPress formatting problem.
Pingback: Do The Hokey Cokey - Nicolas Wu