
Prompted by some recent work I’ve been doing on reasoning about monadic computations, I’ve been looking back at the work from the 1990s by Phil Trinder, Limsoon Wong, Leonidas Fegaras, Torsten Grust, and others, on monad comprehensions as a framework for database queries.
The idea goes back to the adjunction between extension and intension in set theory—you can define a set by its extension, that is by listing its elements:
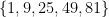
or by its intension, that is by characterizing those elements:

Expressions in the latter form are called set comprehensions. They inspired a programming notation in the SETL language from NYU, and have become widely known through list comprehensions in languages like Haskell. The structure needed of sets or of lists to make this work is roughly that of a monad, and Phil Wadler showed how to generalize comprehensions to arbitrary monads, which led to the “do” notation in Haskell. Around the same time, Phil Trinder showed that comprehensions make a convenient database query language. The comprehension notation has been extended to cover other important aspects of database queries, particularly aggregation and grouping. Monads and aggregations have very nice algebraic structure, which leads to a useful body of laws to support database query optimization.
List comprehensions
Just as a warm-up, here is a reminder about Haskell’s list comprehensions.
![\displaystyle [ 2 \times a + b \mid a \leftarrow [1,2,3] , b \leftarrow [4,5,6] , b \mathbin{\underline{\smash{\mathit{mod}}}} a == 0 ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+2+%5Ctimes+a+%2B+b+%5Cmid+a+%5Cleftarrow+%5B1%2C2%2C3%5D+%2C+b+%5Cleftarrow+%5B4%2C5%2C6%5D+%2C+b+%5Cmathbin%7B%5Cunderline%7B%5Csmash%7B%5Cmathit%7Bmod%7D%7D%7D%7D+a+%3D%3D+0+%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
This (rather concocted) example yields the list of all values of the expression 

![{[1,2,3]}](https://s0.wp.com/latex.php?latex=%7B%5B1%2C2%2C3%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{[4,5,6]}](https://s0.wp.com/latex.php?latex=%7B%5B4%2C5%2C6%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[6,7,8,8,10,12]}](https://s0.wp.com/latex.php?latex=%7B%5B6%2C7%2C8%2C8%2C10%2C12%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
To the left of the vertical bar is the term (an expression). To the right is a comma-separated sequence of qualifiers, each of which is either a generator (of the form 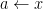

The semantics of list comprehensions is defined by translation; see for example Phil Wadler’s Chapter 7 of The Implementation of Functional Programming Languages. It can be expressed equationally as follows:
![\displaystyle \begin{array}{lcl} [ e \mid \epsilon ] &=& [e] \\ {} [ e \mid b ] &=& \mathbf{if}\;b\;\mathbf{then}\;[ e ]\;\mathbf{else}\;[\,] \\ {} [ e \mid a \leftarrow x ] &=& \mathit{map}\,(\lambda a \mathbin{.} e)\,x \\ {} [ e \mid q, q' ] &=& \mathit{concat}\,[ [ e \mid q' ] \mid q ] \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Blcl%7D+%5B+e+%5Cmid+%5Cepsilon+%5D+%26%3D%26+%5Be%5D+%5C%5C+%7B%7D+%5B+e+%5Cmid+b+%5D+%26%3D%26+%5Cmathbf%7Bif%7D%5C%3Bb%5C%3B%5Cmathbf%7Bthen%7D%5C%3B%5B+e+%5D%5C%3B%5Cmathbf%7Belse%7D%5C%3B%5B%5C%2C%5D+%5C%5C+%7B%7D+%5B+e+%5Cmid+a+%5Cleftarrow+x+%5D+%26%3D%26+%5Cmathit%7Bmap%7D%5C%2C%28%5Clambda+a+%5Cmathbin%7B.%7D+e%29%5C%2Cx+%5C%5C+%7B%7D+%5B+e+%5Cmid+q%2C+q%27+%5D+%26%3D%26+%5Cmathit%7Bconcat%7D%5C%2C%5B+%5B+e+%5Cmid+q%27+%5D+%5Cmid+q+%5D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
(Here, 
Applying this translation to the example at the start of the section gives
![\displaystyle \begin{array}{ll} & [ 2 \times a + b \mid a \leftarrow [1,2,3] , b \leftarrow [4,5,6] , b \mathbin{\underline{\smash{\mathit{mod}}}} a == 0 ] \\ = & \mathit{concat}\,(\mathit{map}\,(\lambda a \mathbin{.} \mathit{concat}\,(\mathit{map}\,(\lambda b \mathbin{.} \mathbf{if}\;b \mathbin{\underline{\smash{\mathit{mod}}}} a == 0\;\mathbf{then}\;[2 \times a + b]\;\mathbf{else}\;[\,])\,[4,5,6]))\,[1,2,3]) \\ = & [6,7,8,8,10,12] \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Bll%7D+%26+%5B+2+%5Ctimes+a+%2B+b+%5Cmid+a+%5Cleftarrow+%5B1%2C2%2C3%5D+%2C+b+%5Cleftarrow+%5B4%2C5%2C6%5D+%2C+b+%5Cmathbin%7B%5Cunderline%7B%5Csmash%7B%5Cmathit%7Bmod%7D%7D%7D%7D+a+%3D%3D+0+%5D+%5C%5C+%3D+%26+%5Cmathit%7Bconcat%7D%5C%2C%28%5Cmathit%7Bmap%7D%5C%2C%28%5Clambda+a+%5Cmathbin%7B.%7D+%5Cmathit%7Bconcat%7D%5C%2C%28%5Cmathit%7Bmap%7D%5C%2C%28%5Clambda+b+%5Cmathbin%7B.%7D+%5Cmathbf%7Bif%7D%5C%3Bb+%5Cmathbin%7B%5Cunderline%7B%5Csmash%7B%5Cmathit%7Bmod%7D%7D%7D%7D+a+%3D%3D+0%5C%3B%5Cmathbf%7Bthen%7D%5C%3B%5B2+%5Ctimes+a+%2B+b%5D%5C%3B%5Cmathbf%7Belse%7D%5C%3B%5B%5C%2C%5D%29%5C%2C%5B4%2C5%2C6%5D%29%29%5C%2C%5B1%2C2%2C3%5D%29+%5C%5C+%3D+%26+%5B6%2C7%2C8%2C8%2C10%2C12%5D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
More generally, a generator may match against a pattern rather than just a variable. In that case, it may bind multiple (or indeed no) variables at once; moreover, the match may fail, in which case it is discarded. This is handled by modifying the translation for generators to use a function defined by pattern-matching, rather than a straight lambda-abstraction:
![\displaystyle [ e \mid p \leftarrow x ] = \mathit{concat}\,(\mathit{map}\,(\lambda a \mathbin{.} \mathbf{case}\;a\;\mathbf{of}\;p \rightarrow [ e ] \;;\; \_ \rightarrow [\,])\,x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+e+%5Cmid+p+%5Cleftarrow+x+%5D+%3D+%5Cmathit%7Bconcat%7D%5C%2C%28%5Cmathit%7Bmap%7D%5C%2C%28%5Clambda+a+%5Cmathbin%7B.%7D+%5Cmathbf%7Bcase%7D%5C%3Ba%5C%3B%5Cmathbf%7Bof%7D%5C%3Bp+%5Crightarrow+%5B+e+%5D+%5C%3B%3B%5C%3B+%5C_+%5Crightarrow+%5B%5C%2C%5D%29%5C%2Cx%29+&bg=ffffff&fg=000000&s=0&c=20201002)
or, more perspicuously,
![\displaystyle [ e \mid p \leftarrow x ] = \mathbf{let}\;h\,p = [ e ] ; h\,\_ = [\,]\;\mathbf{in}\; \mathit{concat}\,(\mathit{map}\,h\,x)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+e+%5Cmid+p+%5Cleftarrow+x+%5D+%3D+%5Cmathbf%7Blet%7D%5C%3Bh%5C%2Cp+%3D+%5B+e+%5D+%3B+h%5C%2C%5C_+%3D+%5B%5C%2C%5D%5C%3B%5Cmathbf%7Bin%7D%5C%3B+%5Cmathit%7Bconcat%7D%5C%2C%28%5Cmathit%7Bmap%7D%5C%2Ch%5C%2Cx%29+&bg=ffffff&fg=000000&s=0&c=20201002)
Monad comprehensions
It is clear from the above translation that the necessary ingredients for list comprehensions are 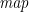
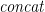
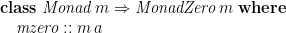
Then the translation for list comprehensions can be generalized to other monads:
![\displaystyle \begin{array}{lcl} [ e \mid \epsilon ] &=& \mathit{return}\,e \\ {} [ e \mid b ] &=& \mathbf{if}\;b\;\mathbf{then}\;\mathit{return}\,e\;\mathbf{else}\;\mathit{mzero} \\ {} [ e \mid p \leftarrow m ] &=& \mathbf{let}\;h\,p = \mathit{return}\,e ; h\,\_ = \mathit{mzero}\;\mathbf{in}\; \mathit{join}\,(\mathit{map}\,h\,m) \\ {} [ e \mid q, q' ] &=& \mathit{join}\,[ [ e \mid q' ] \mid q ] \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Blcl%7D+%5B+e+%5Cmid+%5Cepsilon+%5D+%26%3D%26+%5Cmathit%7Breturn%7D%5C%2Ce+%5C%5C+%7B%7D+%5B+e+%5Cmid+b+%5D+%26%3D%26+%5Cmathbf%7Bif%7D%5C%3Bb%5C%3B%5Cmathbf%7Bthen%7D%5C%3B%5Cmathit%7Breturn%7D%5C%2Ce%5C%3B%5Cmathbf%7Belse%7D%5C%3B%5Cmathit%7Bmzero%7D+%5C%5C+%7B%7D+%5B+e+%5Cmid+p+%5Cleftarrow+m+%5D+%26%3D%26+%5Cmathbf%7Blet%7D%5C%3Bh%5C%2Cp+%3D+%5Cmathit%7Breturn%7D%5C%2Ce+%3B+h%5C%2C%5C_+%3D+%5Cmathit%7Bmzero%7D%5C%3B%5Cmathbf%7Bin%7D%5C%3B+%5Cmathit%7Bjoin%7D%5C%2C%28%5Cmathit%7Bmap%7D%5C%2Ch%5C%2Cm%29+%5C%5C+%7B%7D+%5B+e+%5Cmid+q%2C+q%27+%5D+%26%3D%26+%5Cmathit%7Bjoin%7D%5C%2C%5B+%5B+e+%5Cmid+q%27+%5D+%5Cmid+q+%5D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
(so ![{[ e \mid \epsilon ] = [ e \mid \mathit{True} ]}](https://s0.wp.com/latex.php?latex=%7B%5B+e+%5Cmid+%5Cepsilon+%5D+%3D+%5B+e+%5Cmid+%5Cmathit%7BTrue%7D+%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[ e \mid q ]_\mathsf{List}}](https://s0.wp.com/latex.php?latex=%7B%5B+e+%5Cmid+q+%5D_%5Cmathsf%7BList%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
This translation is different from the one used in the Haskell language specification, which to my mind is a little awkward: the empty list crops up in two different ways in the translation of list comprehensions—for filters, and for generators with patterns—and these are generalized in two different ways to other monads (to the 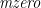
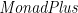
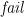

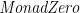
Taking this approach gives basically the monad comprehension notation from Wadler’s Comprehending Monads paper; it loosely corresponds to Haskell’s do notation, except that the term is to the left of a vertical bar rather than at the end, and that filters are just boolean expressions rather than introduced using 
We might impose the law that

or, in terms of comprehensions,
![\displaystyle [ e \mid a \leftarrow \mathit{mzero} ] = \mathit{mzero}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+e+%5Cmid+a+%5Cleftarrow+%5Cmathit%7Bmzero%7D+%5D+%3D+%5Cmathit%7Bmzero%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Informally, this means that any failing steps of the computation cleanly cut off subsequent branches. Conversely, we do not require that
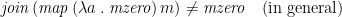
This would have the consequence that a failing step also cleanly erases any effects from earlier parts of the computation, which is too strong a requirement for many monads—particularly those of the “launch missiles now” variety. (The names “left-” and “right zero” make more sense when the equations are expressed in terms of the usual Haskell bind operator 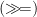
Ringads and collection classes
One more ingredient is needed in order to characterize monads that correspond to “collection classes” such as sets and lists, and that is an analogue of set union or list append. It’s not difficult to see that this is inexpressible in terms of the operations introduced so far: given only collections 

To allow any finite collection to be expressed, it suffices to introduce a binary union operator 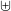

We require composition to distribute over union, in the following sense:
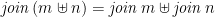
or, in terms of comprehensions,
![\displaystyle [ e \mid a \leftarrow m \uplus n, q ] = [ e \mid a \leftarrow m, q ] \uplus [ e \mid a \leftarrow n, q ]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+e+%5Cmid+a+%5Cleftarrow+m+%5Cuplus+n%2C+q+%5D+%3D+%5B+e+%5Cmid+a+%5Cleftarrow+m%2C+q+%5D+%5Cuplus+%5B+e+%5Cmid+a+%5Cleftarrow+n%2C+q+%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
For the remainder of this post, we will assume a monad in both 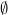
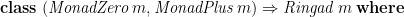
(There are no additional methods; the class 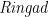
As well as (finite) sets and lists, ringad instances include (finite) bags and a funny kind of binary tree (externally labelled, possibly empty, in which the empty tree is a unit of the binary tree constructor). These are all members of the so-called Boom Hierarchy of types—a name coined by Richard Bird, for an idea due to Hendrik Boom, who by happy coincidence is named for one of these structures in his native language. All members of the Boom Hierarchy are generated from the empty, singleton, and union operators, the difference being whether union is associative, commutative, and idempotent. Another ringad instance, but not a member of the Boom Hierarchy, is the type of probability distributions—either normalized, with a weight-indexed family of union operators, or unnormalized, with an additional scaling operator.
Aggregation
The well-behaved operations over monadic values are called the algebras for that monad—functions 
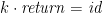

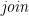
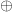
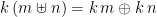
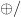

The algebras for a ringad amount to aggregation functions for a collection: the sum of a bag of integers, the maximum of a set of naturals, and so on. We could extend the comprehension notation to encompass aggregations too, for example by adding an optional annotation, writing say “![{[ e \mid q ]^\oplus}](https://s0.wp.com/latex.php?latex=%7B%5B+e+%5Cmid+q+%5D%5E%5Coplus%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{\oplus/\,[e \mid q]}](https://s0.wp.com/latex.php?latex=%7B%5Coplus%2F%5C%2C%5Be+%5Cmid+q%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
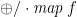
![\displaystyle \mathit{map}\,f\,[e \mid q] = [f\,e \mid q]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathit%7Bmap%7D%5C%2Cf%5C%2C%5Be+%5Cmid+q%5D+%3D+%5Bf%5C%2Ce+%5Cmid+q%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Leonidas Fegaras and David Maier develop a monoid comprehension calculus around such aggregations; but I think their name is inappropriate, because nothing forces the binary aggregating operator to be associative.
Note that, for 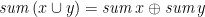
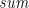
![{[a^2 \mid a \leftarrow x, \mathit{odd}\,a]_\mathsf{Bag}^{+}}](https://s0.wp.com/latex.php?latex=%7B%5Ba%5E2+%5Cmid+a+%5Cleftarrow+x%2C+%5Cmathit%7Bodd%7D%5C%2Ca%5D_%5Cmathsf%7BBag%7D%5E%7B%2B%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[a^2 \mid a \leftarrow x, \mathit{odd}\,a]_\mathsf{Set}^{+}}](https://s0.wp.com/latex.php?latex=%7B%5Ba%5E2+%5Cmid+a+%5Cleftarrow+x%2C+%5Cmathit%7Bodd%7D%5C%2Ca%5D_%5Cmathsf%7BSet%7D%5E%7B%2B%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
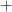
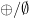
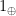
We can derive translation rules for aggregations from the definition
![\displaystyle [ e \mid q ]^\oplus = \oplus/\,[e \mid q]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+e+%5Cmid+q+%5D%5E%5Coplus+%3D+%5Coplus%2F%5C%2C%5Be+%5Cmid+q%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
For empty aggregations, we have:
![\displaystyle \begin{array}{ll} & [ e \mid \epsilon ]^\oplus \\ = & \qquad \{ \mbox{aggregation} \} \\ & \oplus/\,[ e \mid \epsilon ] \\ = & \qquad \{ \mbox{comprehension} \} \\ & \oplus/\,(\mathit{return}\,e) \\ = & \qquad \{ \mbox{monad algebra} \} \\ & e \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Bll%7D+%26+%5B+e+%5Cmid+%5Cepsilon+%5D%5E%5Coplus+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Baggregation%7D+%5C%7D+%5C%5C+%26+%5Coplus%2F%5C%2C%5B+e+%5Cmid+%5Cepsilon+%5D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bcomprehension%7D+%5C%7D+%5C%5C+%26+%5Coplus%2F%5C%2C%28%5Cmathit%7Breturn%7D%5C%2Ce%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bmonad+algebra%7D+%5C%7D+%5C%5C+%26+e+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
For filters, we have:
![\displaystyle \begin{array}{ll} & [ e \mid b ]^\oplus \\ = & \qquad \{ \mbox{aggregation} \} \\ & \oplus/\,[ e \mid b ] \\ = & \qquad \{ \mbox{comprehension} \} \\ & \oplus/\,(\mathbf{if}\;b\;\mathbf{then}\;\mathit{return}\,e\;\mathbf{else}\;\emptyset) \\ = & \qquad \{ \mbox{lift out the conditional} \} \\ & \mathbf{if}\;b\;\mathbf{then}\;{\oplus/}\,(\mathit{return}\,e)\;\mathbf{else}\;{\oplus/}\,\emptyset \\ = & \qquad \{ \mbox{ringad algebra} \} \\ & \mathbf{if}\;b\;\mathbf{then}\;e\;\mathbf{else}\;1_\oplus \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Bll%7D+%26+%5B+e+%5Cmid+b+%5D%5E%5Coplus+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Baggregation%7D+%5C%7D+%5C%5C+%26+%5Coplus%2F%5C%2C%5B+e+%5Cmid+b+%5D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bcomprehension%7D+%5C%7D+%5C%5C+%26+%5Coplus%2F%5C%2C%28%5Cmathbf%7Bif%7D%5C%3Bb%5C%3B%5Cmathbf%7Bthen%7D%5C%3B%5Cmathit%7Breturn%7D%5C%2Ce%5C%3B%5Cmathbf%7Belse%7D%5C%3B%5Cemptyset%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Blift+out+the+conditional%7D+%5C%7D+%5C%5C+%26+%5Cmathbf%7Bif%7D%5C%3Bb%5C%3B%5Cmathbf%7Bthen%7D%5C%3B%7B%5Coplus%2F%7D%5C%2C%28%5Cmathit%7Breturn%7D%5C%2Ce%29%5C%3B%5Cmathbf%7Belse%7D%5C%3B%7B%5Coplus%2F%7D%5C%2C%5Cemptyset+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bringad+algebra%7D+%5C%7D+%5C%5C+%26+%5Cmathbf%7Bif%7D%5C%3Bb%5C%3B%5Cmathbf%7Bthen%7D%5C%3Be%5C%3B%5Cmathbf%7Belse%7D%5C%3B1_%5Coplus+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
For generators, we have:
![\displaystyle \begin{array}{ll} & [ e \mid p \leftarrow m ]^\oplus \\ = & \qquad \{ \mbox{aggregation} \} \\ & \oplus/\,[ e \mid p \leftarrow m ] \\ = & \qquad \{ \mbox{comprehension} \} \\ & \oplus/\,(\mathbf{let}\;h\,p = \mathit{return}\,e ; h\,\_ = \emptyset\;\mathbf{in}\;\mathit{join}\,(\mathit{map}\,h\,m)) \\ = & \qquad \{ \mbox{lift out the \textbf{let}} \} \\ & \mathbf{let}\;h\,p = \mathit{return},e ; h\,\_ = \emptyset\;\mathbf{in}\;{\oplus/}\,(\mathit{join}\,(\mathit{map}\,h\,m)) \\ = & \qquad \{ \mbox{monad algebra} \} \\ & \mathbf{let}\;h\,p = \mathit{return}\,e ; h\,\_ = \emptyset\;\mathbf{in}\;{\oplus/}\,(\mathit{map}\,(\oplus/)\,(\mathit{map}\,h\,m)) \\ = & \qquad \{ \mbox{functors} \} \\ & \mathbf{let}\;h\,p = \mathit{return}\,e ; h\,\_ = \emptyset\;\mathbf{in}\;{\oplus/}\,(\mathit{map}\,(\oplus/ \cdot h)\,m) \\ = & \qquad \{ \mbox{let~} h' = \oplus/ \cdot h \} \\ & \mathbf{let}\;h'\,p = \oplus/\,(\mathit{return}\,e) ; h'\,\_ = \oplus/\,\emptyset\;\mathbf{in}\;{\oplus/}\,(\mathit{map}\,h'\,m) \\ = & \qquad \{ \mbox{ringad algebra} \} \\ & \mathbf{let}\;h'\,p = e ; h'\,\_ = 1_\oplus\;\mathbf{in}\;{\oplus/}\,(\mathit{map}\,h'\,m) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Bll%7D+%26+%5B+e+%5Cmid+p+%5Cleftarrow+m+%5D%5E%5Coplus+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Baggregation%7D+%5C%7D+%5C%5C+%26+%5Coplus%2F%5C%2C%5B+e+%5Cmid+p+%5Cleftarrow+m+%5D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bcomprehension%7D+%5C%7D+%5C%5C+%26+%5Coplus%2F%5C%2C%28%5Cmathbf%7Blet%7D%5C%3Bh%5C%2Cp+%3D+%5Cmathit%7Breturn%7D%5C%2Ce+%3B+h%5C%2C%5C_+%3D+%5Cemptyset%5C%3B%5Cmathbf%7Bin%7D%5C%3B%5Cmathit%7Bjoin%7D%5C%2C%28%5Cmathit%7Bmap%7D%5C%2Ch%5C%2Cm%29%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Blift+out+the+%5Ctextbf%7Blet%7D%7D+%5C%7D+%5C%5C+%26+%5Cmathbf%7Blet%7D%5C%3Bh%5C%2Cp+%3D+%5Cmathit%7Breturn%7D%2Ce+%3B+h%5C%2C%5C_+%3D+%5Cemptyset%5C%3B%5Cmathbf%7Bin%7D%5C%3B%7B%5Coplus%2F%7D%5C%2C%28%5Cmathit%7Bjoin%7D%5C%2C%28%5Cmathit%7Bmap%7D%5C%2Ch%5C%2Cm%29%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bmonad+algebra%7D+%5C%7D+%5C%5C+%26+%5Cmathbf%7Blet%7D%5C%3Bh%5C%2Cp+%3D+%5Cmathit%7Breturn%7D%5C%2Ce+%3B+h%5C%2C%5C_+%3D+%5Cemptyset%5C%3B%5Cmathbf%7Bin%7D%5C%3B%7B%5Coplus%2F%7D%5C%2C%28%5Cmathit%7Bmap%7D%5C%2C%28%5Coplus%2F%29%5C%2C%28%5Cmathit%7Bmap%7D%5C%2Ch%5C%2Cm%29%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bfunctors%7D+%5C%7D+%5C%5C+%26+%5Cmathbf%7Blet%7D%5C%3Bh%5C%2Cp+%3D+%5Cmathit%7Breturn%7D%5C%2Ce+%3B+h%5C%2C%5C_+%3D+%5Cemptyset%5C%3B%5Cmathbf%7Bin%7D%5C%3B%7B%5Coplus%2F%7D%5C%2C%28%5Cmathit%7Bmap%7D%5C%2C%28%5Coplus%2F+%5Ccdot+h%29%5C%2Cm%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Blet%7E%7D+h%27+%3D+%5Coplus%2F+%5Ccdot+h+%5C%7D+%5C%5C+%26+%5Cmathbf%7Blet%7D%5C%3Bh%27%5C%2Cp+%3D+%5Coplus%2F%5C%2C%28%5Cmathit%7Breturn%7D%5C%2Ce%29+%3B+h%27%5C%2C%5C_+%3D+%5Coplus%2F%5C%2C%5Cemptyset%5C%3B%5Cmathbf%7Bin%7D%5C%3B%7B%5Coplus%2F%7D%5C%2C%28%5Cmathit%7Bmap%7D%5C%2Ch%27%5C%2Cm%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bringad+algebra%7D+%5C%7D+%5C%5C+%26+%5Cmathbf%7Blet%7D%5C%3Bh%27%5C%2Cp+%3D+e+%3B+h%27%5C%2C%5C_+%3D+1_%5Coplus%5C%3B%5Cmathbf%7Bin%7D%5C%3B%7B%5Coplus%2F%7D%5C%2C%28%5Cmathit%7Bmap%7D%5C%2Ch%27%5C%2Cm%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
And for sequences of qualifiers, we have:
![\displaystyle \begin{array}{ll} & [ e \mid q, q' ]^\oplus \\ = & \qquad \{ \mbox{aggregation} \} \\ & \oplus/\,[ e \mid q, q' ] \\ = & \qquad \{ \mbox{comprehension} \} \\ & \oplus/\,(\mathit{join}\,[ [ e \mid q'] \mid q ] \\ = & \qquad \{ \mbox{monad algebra} \} \\ & \oplus/\,(\mathit{map}\,(\oplus/)\,[ [ e \mid q'] \mid q ]) \\ = & \qquad \{ \mbox{map over comprehension} \} \\ & \oplus/\,[ \oplus/\,[ e \mid q'] \mid q ] \\ = & \qquad \{ \mbox{aggregation} \} \\ & [ [ e \mid q']^\oplus \mid q ]^\oplus \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Bll%7D+%26+%5B+e+%5Cmid+q%2C+q%27+%5D%5E%5Coplus+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Baggregation%7D+%5C%7D+%5C%5C+%26+%5Coplus%2F%5C%2C%5B+e+%5Cmid+q%2C+q%27+%5D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bcomprehension%7D+%5C%7D+%5C%5C+%26+%5Coplus%2F%5C%2C%28%5Cmathit%7Bjoin%7D%5C%2C%5B+%5B+e+%5Cmid+q%27%5D+%5Cmid+q+%5D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bmonad+algebra%7D+%5C%7D+%5C%5C+%26+%5Coplus%2F%5C%2C%28%5Cmathit%7Bmap%7D%5C%2C%28%5Coplus%2F%29%5C%2C%5B+%5B+e+%5Cmid+q%27%5D+%5Cmid+q+%5D%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bmap+over+comprehension%7D+%5C%7D+%5C%5C+%26+%5Coplus%2F%5C%2C%5B+%5Coplus%2F%5C%2C%5B+e+%5Cmid+q%27%5D+%5Cmid+q+%5D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Baggregation%7D+%5C%7D+%5C%5C+%26+%5B+%5B+e+%5Cmid+q%27%5D%5E%5Coplus+%5Cmid+q+%5D%5E%5Coplus+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Putting all this together, we have:
![\displaystyle \begin{array}{lcl} [ e \mid \epsilon ]^\oplus &=& e \\ {} [ e \mid b ]^\oplus &=&\mathbf{if}\;b\;\mathbf{then}\;e\;\mathbf{else}\;1_\oplus \\ {} [ e \mid p \leftarrow m ]^\oplus &=& \mathbf{let}\;h\,p = e ; h\,\_ = 1_\oplus\;\mathbf{in}\;{\oplus/}\,(\mathit{map}\,h\,m) \\ {} [ e \mid q, q' ]^\oplus &=& [ [ e \mid q']^\oplus \mid q ]^\oplus \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Blcl%7D+%5B+e+%5Cmid+%5Cepsilon+%5D%5E%5Coplus+%26%3D%26+e+%5C%5C+%7B%7D+%5B+e+%5Cmid+b+%5D%5E%5Coplus+%26%3D%26%5Cmathbf%7Bif%7D%5C%3Bb%5C%3B%5Cmathbf%7Bthen%7D%5C%3Be%5C%3B%5Cmathbf%7Belse%7D%5C%3B1_%5Coplus+%5C%5C+%7B%7D+%5B+e+%5Cmid+p+%5Cleftarrow+m+%5D%5E%5Coplus+%26%3D%26+%5Cmathbf%7Blet%7D%5C%3Bh%5C%2Cp+%3D+e+%3B+h%5C%2C%5C_+%3D+1_%5Coplus%5C%3B%5Cmathbf%7Bin%7D%5C%3B%7B%5Coplus%2F%7D%5C%2C%28%5Cmathit%7Bmap%7D%5C%2Ch%5C%2Cm%29+%5C%5C+%7B%7D+%5B+e+%5Cmid+q%2C+q%27+%5D%5E%5Coplus+%26%3D%26+%5B+%5B+e+%5Cmid+q%27%5D%5E%5Coplus+%5Cmid+q+%5D%5E%5Coplus+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Heterogeneous comprehensions
We have seen that comprehensions can be interpreted in an arbitrary ringad; for example, ![{[a^2 \mid a \leftarrow x, \mathit{odd}\,a]_\mathsf{Set}}](https://s0.wp.com/latex.php?latex=%7B%5Ba%5E2+%5Cmid+a+%5Cleftarrow+x%2C+%5Cmathit%7Bodd%7D%5C%2Ca%5D_%5Cmathsf%7BSet%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[a^2 \mid a \leftarrow x, \mathit{odd}\,a]_\mathsf{Bag}}](https://s0.wp.com/latex.php?latex=%7B%5Ba%5E2+%5Cmid+a+%5Cleftarrow+x%2C+%5Cmathit%7Bodd%7D%5C%2Ca%5D_%5Cmathsf%7BBag%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Let’s introduced the notion of a ringad morphism, extending the familiar analogue on monads. For monads 
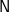
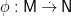
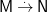
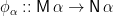

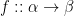

A ringad morphism 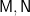
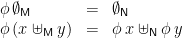
Then a ringad morphism behaves nicely with respect to ringad comprehensions—a comprehension interpreted in ringad
![\displaystyle \begin{array}{ll} & \phi\,[ e \mid \epsilon ]_\mathsf{M} \\ = & \qquad \{ \mbox{comprehension} \} \\ & \phi\,(\mathit{return}_\mathsf{M}\,e) \\ = & \qquad \{ \mbox{ringad morphism} \} \\ & \mathit{return}_\mathsf{N}\,e \\ = & \qquad \{ \mbox{comprehension} \} \\ & [e \mid \epsilon ]_\mathsf{N} \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Bll%7D+%26+%5Cphi%5C%2C%5B+e+%5Cmid+%5Cepsilon+%5D_%5Cmathsf%7BM%7D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bcomprehension%7D+%5C%7D+%5C%5C+%26+%5Cphi%5C%2C%28%5Cmathit%7Breturn%7D_%5Cmathsf%7BM%7D%5C%2Ce%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bringad+morphism%7D+%5C%7D+%5C%5C+%26+%5Cmathit%7Breturn%7D_%5Cmathsf%7BN%7D%5C%2Ce+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bcomprehension%7D+%5C%7D+%5C%5C+%26+%5Be+%5Cmid+%5Cepsilon+%5D_%5Cmathsf%7BN%7D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
For filters, we have:
![\displaystyle \begin{array}{ll} & \phi\,[ e \mid b ]_\mathsf{M} \\ = & \qquad \{ \mbox{comprehension} \} \\ & \phi\,(\mathbf{if}\;b\;\mathbf{then}\;\mathit{return}_\mathsf{M}\,e\;\mathbf{else}\;\emptyset_\mathsf{M}) \\ = & \qquad \{ \mbox{lift out the conditional} \} \\ & \mathbf{if}\;b\;\mathbf{then}\;\phi\,(\mathit{return}_\mathsf{M}\,e)\;\mathbf{else}\;\phi\,\emptyset_\mathsf{M} \\ = & \qquad \{ \mbox{ringad morphism} \} \\ & \mathbf{if}\;b\;\mathbf{then}\;\mathit{return}_\mathsf{N}\,e\;\mathbf{else}\;\emptyset_\mathsf{N} \\ = & \qquad \{ \mbox{comprehension} \} \\ & [ e \mid b ]_\mathsf{N} \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Bll%7D+%26+%5Cphi%5C%2C%5B+e+%5Cmid+b+%5D_%5Cmathsf%7BM%7D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bcomprehension%7D+%5C%7D+%5C%5C+%26+%5Cphi%5C%2C%28%5Cmathbf%7Bif%7D%5C%3Bb%5C%3B%5Cmathbf%7Bthen%7D%5C%3B%5Cmathit%7Breturn%7D_%5Cmathsf%7BM%7D%5C%2Ce%5C%3B%5Cmathbf%7Belse%7D%5C%3B%5Cemptyset_%5Cmathsf%7BM%7D%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Blift+out+the+conditional%7D+%5C%7D+%5C%5C+%26+%5Cmathbf%7Bif%7D%5C%3Bb%5C%3B%5Cmathbf%7Bthen%7D%5C%3B%5Cphi%5C%2C%28%5Cmathit%7Breturn%7D_%5Cmathsf%7BM%7D%5C%2Ce%29%5C%3B%5Cmathbf%7Belse%7D%5C%3B%5Cphi%5C%2C%5Cemptyset_%5Cmathsf%7BM%7D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bringad+morphism%7D+%5C%7D+%5C%5C+%26+%5Cmathbf%7Bif%7D%5C%3Bb%5C%3B%5Cmathbf%7Bthen%7D%5C%3B%5Cmathit%7Breturn%7D_%5Cmathsf%7BN%7D%5C%2Ce%5C%3B%5Cmathbf%7Belse%7D%5C%3B%5Cemptyset_%5Cmathsf%7BN%7D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bcomprehension%7D+%5C%7D+%5C%5C+%26+%5B+e+%5Cmid+b+%5D_%5Cmathsf%7BN%7D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
For generators:
![\displaystyle \begin{array}{ll} & \phi\,[ e \mid p \leftarrow m ]_\mathsf{M} \\ = & \qquad \{ \mbox{comprehension} \} \\ & \phi\,(\mathbf{let}\;h\,p = \mathit{return}_\mathsf{M}\,e ; h\,\_ = \emptyset_\mathsf{M}\;\mathbf{in}\;\mathit{join}_\mathsf{M}\,(\mathit{map}_\mathsf{M}\,h\,m)) \\ = & \qquad \{ \mbox{lift out the \textbf{let}} \} \\ & \mathbf{let}\;h\,p = \mathit{return}_\mathsf{M}\,e ; h\,\_ = \emptyset_\mathsf{M}\;\mathbf{in}\;\phi\,(\mathit{join}_\mathsf{M}\,(\mathit{map}_\mathsf{M}\,h\,m)) \\ = & \qquad \{ \mbox{ringad morphism, functors} \} \\ & \mathbf{let}\;h\,p = \mathit{return}_\mathsf{M}\,e ; h\,\_ = \emptyset_\mathsf{M}\;\mathbf{in}\;\mathit{join}_\mathsf{N}\,(\phi\,(\mathit{map}_\mathsf{M}\,(\phi \cdot h)\,m)) \\ = & \qquad \{ \mbox{let~} h' = \phi \cdot h \} \\ & \mathbf{let}\;h'\,p = \phi\,(\mathit{return}_\mathsf{M}\,e) ; h'\,\_ = \phi\,\emptyset_\mathsf{M}\;\mathbf{in}\;\mathit{join}_\mathsf{N}\,(\phi\,(\mathit{map}_\mathsf{M}\,h'\,m)) \\ = & \qquad \{ \mbox{ringad morphism, induction} \} \\ & \mathbf{let}\;h'\,p = \mathit{return}_\mathsf{N}\,e ; h'\,\_ = \emptyset_\mathsf{N}\;\mathbf{in}\;\mathit{join}_\mathsf{N}\,(\phi\,(\mathit{map}_\mathsf{M}\,h'\,m)) \\ = & \qquad \{ \mbox{naturality of~} \phi \} \\ & \mathbf{let}\;h'\,p = \mathit{return}_\mathsf{N}\,e ; h'\,\_ = \emptyset_\mathsf{N}\;\mathbf{in}\;\mathit{join}_\mathsf{N}\,(\mathit{map}_\mathsf{N}\,h'\,(\phi\,m)) \\ = & \qquad \{ \mbox{comprehension} \} \\ & [ e \mid p \leftarrow \phi\,m ]_\mathsf{N} \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Bll%7D+%26+%5Cphi%5C%2C%5B+e+%5Cmid+p+%5Cleftarrow+m+%5D_%5Cmathsf%7BM%7D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bcomprehension%7D+%5C%7D+%5C%5C+%26+%5Cphi%5C%2C%28%5Cmathbf%7Blet%7D%5C%3Bh%5C%2Cp+%3D+%5Cmathit%7Breturn%7D_%5Cmathsf%7BM%7D%5C%2Ce+%3B+h%5C%2C%5C_+%3D+%5Cemptyset_%5Cmathsf%7BM%7D%5C%3B%5Cmathbf%7Bin%7D%5C%3B%5Cmathit%7Bjoin%7D_%5Cmathsf%7BM%7D%5C%2C%28%5Cmathit%7Bmap%7D_%5Cmathsf%7BM%7D%5C%2Ch%5C%2Cm%29%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Blift+out+the+%5Ctextbf%7Blet%7D%7D+%5C%7D+%5C%5C+%26+%5Cmathbf%7Blet%7D%5C%3Bh%5C%2Cp+%3D+%5Cmathit%7Breturn%7D_%5Cmathsf%7BM%7D%5C%2Ce+%3B+h%5C%2C%5C_+%3D+%5Cemptyset_%5Cmathsf%7BM%7D%5C%3B%5Cmathbf%7Bin%7D%5C%3B%5Cphi%5C%2C%28%5Cmathit%7Bjoin%7D_%5Cmathsf%7BM%7D%5C%2C%28%5Cmathit%7Bmap%7D_%5Cmathsf%7BM%7D%5C%2Ch%5C%2Cm%29%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bringad+morphism%2C+functors%7D+%5C%7D+%5C%5C+%26+%5Cmathbf%7Blet%7D%5C%3Bh%5C%2Cp+%3D+%5Cmathit%7Breturn%7D_%5Cmathsf%7BM%7D%5C%2Ce+%3B+h%5C%2C%5C_+%3D+%5Cemptyset_%5Cmathsf%7BM%7D%5C%3B%5Cmathbf%7Bin%7D%5C%3B%5Cmathit%7Bjoin%7D_%5Cmathsf%7BN%7D%5C%2C%28%5Cphi%5C%2C%28%5Cmathit%7Bmap%7D_%5Cmathsf%7BM%7D%5C%2C%28%5Cphi+%5Ccdot+h%29%5C%2Cm%29%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Blet%7E%7D+h%27+%3D+%5Cphi+%5Ccdot+h+%5C%7D+%5C%5C+%26+%5Cmathbf%7Blet%7D%5C%3Bh%27%5C%2Cp+%3D+%5Cphi%5C%2C%28%5Cmathit%7Breturn%7D_%5Cmathsf%7BM%7D%5C%2Ce%29+%3B+h%27%5C%2C%5C_+%3D+%5Cphi%5C%2C%5Cemptyset_%5Cmathsf%7BM%7D%5C%3B%5Cmathbf%7Bin%7D%5C%3B%5Cmathit%7Bjoin%7D_%5Cmathsf%7BN%7D%5C%2C%28%5Cphi%5C%2C%28%5Cmathit%7Bmap%7D_%5Cmathsf%7BM%7D%5C%2Ch%27%5C%2Cm%29%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bringad+morphism%2C+induction%7D+%5C%7D+%5C%5C+%26+%5Cmathbf%7Blet%7D%5C%3Bh%27%5C%2Cp+%3D+%5Cmathit%7Breturn%7D_%5Cmathsf%7BN%7D%5C%2Ce+%3B+h%27%5C%2C%5C_+%3D+%5Cemptyset_%5Cmathsf%7BN%7D%5C%3B%5Cmathbf%7Bin%7D%5C%3B%5Cmathit%7Bjoin%7D_%5Cmathsf%7BN%7D%5C%2C%28%5Cphi%5C%2C%28%5Cmathit%7Bmap%7D_%5Cmathsf%7BM%7D%5C%2Ch%27%5C%2Cm%29%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bnaturality+of%7E%7D+%5Cphi+%5C%7D+%5C%5C+%26+%5Cmathbf%7Blet%7D%5C%3Bh%27%5C%2Cp+%3D+%5Cmathit%7Breturn%7D_%5Cmathsf%7BN%7D%5C%2Ce+%3B+h%27%5C%2C%5C_+%3D+%5Cemptyset_%5Cmathsf%7BN%7D%5C%3B%5Cmathbf%7Bin%7D%5C%3B%5Cmathit%7Bjoin%7D_%5Cmathsf%7BN%7D%5C%2C%28%5Cmathit%7Bmap%7D_%5Cmathsf%7BN%7D%5C%2Ch%27%5C%2C%28%5Cphi%5C%2Cm%29%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bcomprehension%7D+%5C%7D+%5C%5C+%26+%5B+e+%5Cmid+p+%5Cleftarrow+%5Cphi%5C%2Cm+%5D_%5Cmathsf%7BN%7D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
And for sequences of qualifiers:
![\displaystyle \begin{array}{ll} & \phi\,[ e \mid q, q' ]_\mathsf{M} \\ = & \qquad \{ \mbox{comprehension} \} \\ & \phi\,(\mathit{join}\,[ [ e \mid q' ]_\mathsf{M} \mid q ]_\mathsf{M}) \\ = & \qquad \{ \mbox{ringad morphism} \} \\ & \phi\,(\mathit{map}\,\phi\,[ [ e \mid q' ]_\mathsf{M} \mid q ]_\mathsf{M}) \\ = & \qquad \{ \mbox{map over comprehension} \} \\ & \phi\,[ \phi\,[ e \mid q' ]_\mathsf{M} \mid q ]_\mathsf{M} \\ = & \qquad \{ \mbox{induction} \} \\ & [ [ e \mid q' ]_\mathsf{N} \mid q ]_\mathsf{N} \\ = & \qquad \{ \mbox{comprehension} \} \\ & [ e \mid q, q' ]_\mathsf{N} \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Bll%7D+%26+%5Cphi%5C%2C%5B+e+%5Cmid+q%2C+q%27+%5D_%5Cmathsf%7BM%7D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bcomprehension%7D+%5C%7D+%5C%5C+%26+%5Cphi%5C%2C%28%5Cmathit%7Bjoin%7D%5C%2C%5B+%5B+e+%5Cmid+q%27+%5D_%5Cmathsf%7BM%7D+%5Cmid+q+%5D_%5Cmathsf%7BM%7D%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bringad+morphism%7D+%5C%7D+%5C%5C+%26+%5Cphi%5C%2C%28%5Cmathit%7Bmap%7D%5C%2C%5Cphi%5C%2C%5B+%5B+e+%5Cmid+q%27+%5D_%5Cmathsf%7BM%7D+%5Cmid+q+%5D_%5Cmathsf%7BM%7D%29+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bmap+over+comprehension%7D+%5C%7D+%5C%5C+%26+%5Cphi%5C%2C%5B+%5Cphi%5C%2C%5B+e+%5Cmid+q%27+%5D_%5Cmathsf%7BM%7D+%5Cmid+q+%5D_%5Cmathsf%7BM%7D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Binduction%7D+%5C%7D+%5C%5C+%26+%5B+%5B+e+%5Cmid+q%27+%5D_%5Cmathsf%7BN%7D+%5Cmid+q+%5D_%5Cmathsf%7BN%7D+%5C%5C+%3D+%26+%5Cqquad+%5C%7B+%5Cmbox%7Bcomprehension%7D+%5C%7D+%5C%5C+%26+%5B+e+%5Cmid+q%2C+q%27+%5D_%5Cmathsf%7BN%7D+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
For example, if 
![\displaystyle \mathit{bag2set}\,[a^2 \mid a \leftarrow x, \mathit{odd}\,a]_\mathsf{Bag} = [a^2 \mid a \leftarrow \mathit{bag2set}\,x, \mathit{odd}\,a]_\mathsf{Set}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cmathit%7Bbag2set%7D%5C%2C%5Ba%5E2+%5Cmid+a+%5Cleftarrow+x%2C+%5Cmathit%7Bodd%7D%5C%2Ca%5D_%5Cmathsf%7BBag%7D+%3D+%5Ba%5E2+%5Cmid+a+%5Cleftarrow+%5Cmathit%7Bbag2set%7D%5C%2Cx%2C+%5Cmathit%7Bodd%7D%5C%2Ca%5D_%5Cmathsf%7BSet%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
and both yield the set of squares of the odd members of 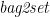
![\displaystyle [ a+b \mid a \leftarrow [1,2,3], b \leftarrow \langle4,4,5\rangle ]_\mathsf{Set} = \{ 5,6,7,8 \}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+a%2Bb+%5Cmid+a+%5Cleftarrow+%5B1%2C2%2C3%5D%2C+b+%5Cleftarrow+%5Clangle4%2C4%2C5%5Crangle+%5D_%5Cmathsf%7BSet%7D+%3D+%5C%7B+5%2C6%2C7%2C8+%5C%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
(writing 
![\displaystyle [ a+b \mid a \leftarrow \mathit{list2set}\,[1,2,3], b \leftarrow \mathit{bag2set}\,\langle4,4,5\rangle ]_\mathsf{Set} = \{ 5,6,7,8 \}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5B+a%2Bb+%5Cmid+a+%5Cleftarrow+%5Cmathit%7Blist2set%7D%5C%2C%5B1%2C2%2C3%5D%2C+b+%5Cleftarrow+%5Cmathit%7Bbag2set%7D%5C%2C%5Clangle4%2C4%2C5%5Crangle+%5D_%5Cmathsf%7BSet%7D+%3D+%5C%7B+5%2C6%2C7%2C8+%5C%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
There is a forgetful function from any poorer member of the Boom hierarchy to a richer one, flattening some distinctions by imposing additional laws—for example, from bags to sets, flattening distinctions concerning multiplicity—and I would class these forgetful functions as “obvious” morphisms. On the other hand, any morphisms in the opposite direction—such as sorting, from bags to lists, and one-of-each, from sets to bags—are not “obvious”, and so should not be elided; and similarly, I’m not sure that I could justify as “obvious” any morphisms involving non-members of the Boom Hierarchy, such as probability distributions.

Monad comprehensions in Haskell 1.4 used MonadZero for matches, and there was no fail in Monad. However, there was also an extra notion of an unfailable pattern, which allowed the following to not use MonadZero:
[ x + y | (x, y) <- l ]
(x, y) is an unfailable pattern because it can only be refuted by bottom. For Haskell 98, unfailable patterns were removed, but it was deemed unacceptable for the above code to use MonadZero, so fail was added instead, and all Monads were given the ability to have arbitrary matches in a weird compromise.
Shouldn’t those bag- and set-using comprehensions’ filter be “odd a,” vice “odd x”?
Or is that an established conventional meaning?
(I Am Not A Mathematician, I just play one on the Internet…)
Oops. Fixed – thanks.
I’m a little bit surprised that you don’t mention concatMap and use it in the translation of list comprehensions as it is the (>>=) of the list monad and makes the generalization from lists to monads even clearer.
I think it’s generally a matter of taste whether to use concat and join or concatMap and bind; they’re equivalent. But imho, algebras for a monad come out much cleaner with join than with bind.
Fair enough.
Considering just the translation of monad comprehensions I personally prefer the version using (>>=) over the one using join though.
Having just begun to study probability, I found your little facts concerning probability distributions quite intriguing: can you recommend any sources where one might explore further?
Quite a few people have written about probability distributions as a monad; there are some references in the “Just Do It” paper linked above (ie http://www.cs.ox.ac.uk/publications/publication4877-abstract.html).
Reblogged this on Adil Akhter.
Sorry for being slow, but what’s the meaning of #/ (for some function #)?
Its meaning is determined in the first paragraph of the section headed “Aggregation”. Think of them as folds using the binary operator to aggregate collections. For example, +/ sums a collection of numbers.